
Somos partners gold de Microsoft y quizás podría parecer que esta entrada es tendenciosa, pero la realidad es que siendo imparciales, #Azure Data Factory es una herramienta increíble, quizás, de lo mejor que hay un Azure junto con #DataBricks y #Synapse para la parte de datos.
¿Que es Data Factory?
Comencemos mencionando que es una herramienta totalmente administrada, basada en proveer servicios de integración de datos y #ETL que permite orquestar el transito de datos y las transformaciones.
Como característica adicional podemos mencionar que se adapta al pequeño cambio de #ETL a #ELT para modelos de #datalakes. Recordemos que ETL significa Extraer, Transformar y Cargar, mientras que ELT significa Extraer, Cargar y Transformar. En ETL, los datos fluyen desde la fuente de datos hasta la preparación y el destino de los datos. ELT permite que el destino de los datos realice la transformación, eliminando la necesidad de almacenar los datos. En esta nota hay mas informacion al respecto.
Por otro lado, y super importante de remarcar. ADF es la herramienta que “absorbe” los paquetes de SSIS cuando se lleva una base #MSSQL de on-premise a la nube.
Veamos a detalle. ¿Que puede hacer #ADF por nosotros?
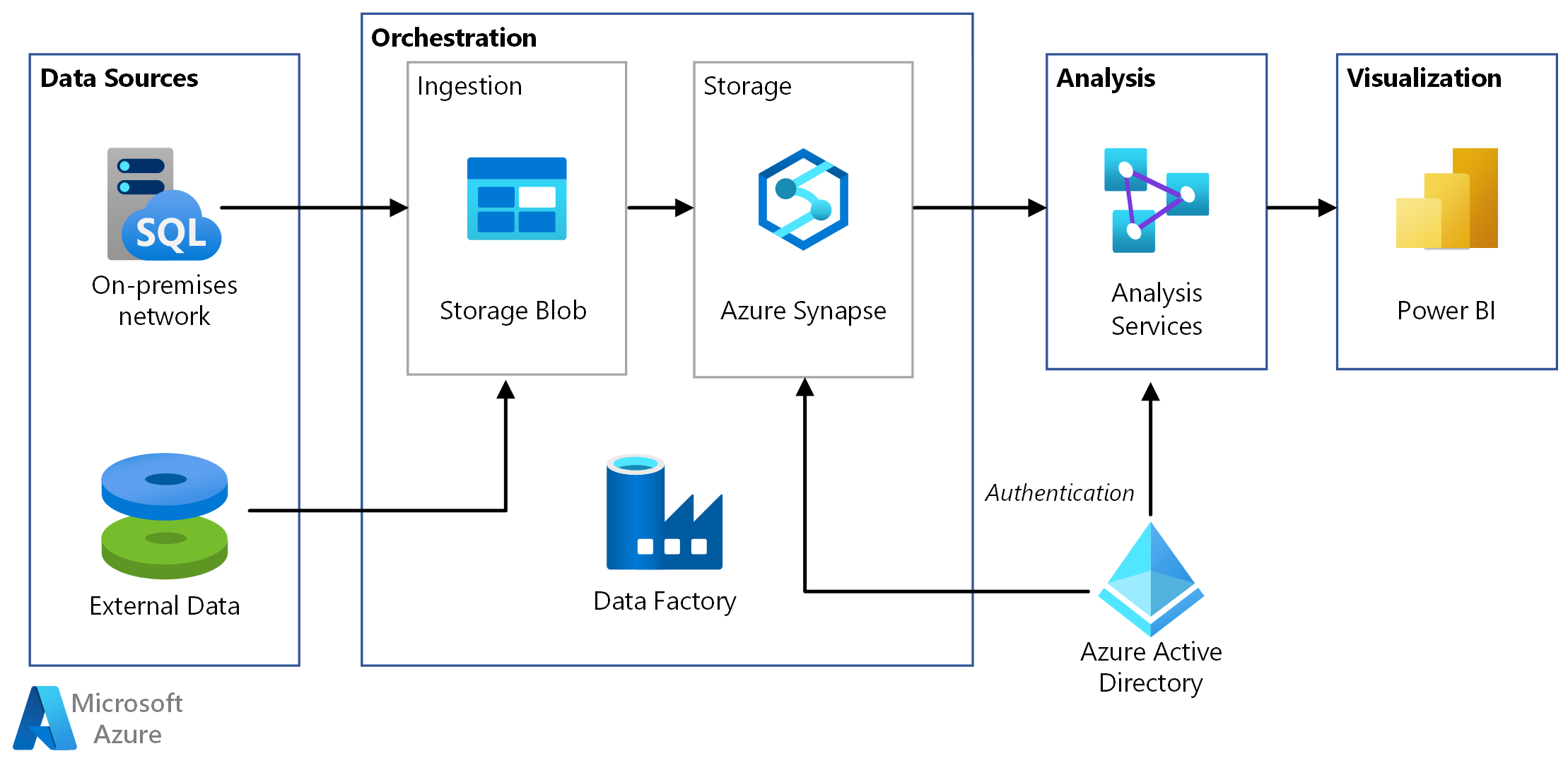
Estas son algunas características necesarias para correr ADF:
Pipelines: un pipeline es una agrupación de actividades que es realizada como un proceso integrado. En un solo pipeline se pueden ejecutar todas las acciones referidas a la manipulación de datos necesaria por un proceso.
Activities: son justamente las actividades que se corren como parte de un pipeline. Son una acción explicita, como copiar datos a una tabla de almacenamiento o transformar datos.
Dataset: los conjuntos de datos son estructuras de datos dentro de los almacenes de datos, que apuntan a los datos que las actividades necesitan utilizar como entradas o salidas.
Triggers: estos triggers o en español desencadenantes son una forma de correr una ejecución de pipeline. Los desencadenadores determinan cuándo debe comenzar la ejecución de un pipeline, de acuerdo a 3 tipos de activadores:
- Programado : este activador invoca una canalización a una hora programada.
- Tumbling windows trigger : este desencadenador opera en un intervalo periódico.
- Basado en evento: un activador que invoca una ejecución de pipeline cuando hay un determinado evento.
Tiempo de ejecución de integración: El tiempo de ejecución de integración (IR) es la infraestructura informática que se utiliza para proporcionar capacidades de integración de datos como flujo de datos, movimiento de datos, envío de actividades y ejecución de paquetes SSIS. Hay tres tipos de tiempos de ejecución de integración disponibles, que son:
- Azure, para Flujo de datos, movimiento de datos, envío de actividades
- Self hosted, para Movimiento de datos, envío de actividades
- SSIS, para la ejecución de paquetes #SSIS (integration services de SQL)
¿Que alternativas existen a Data Factory?
Si vamos a un esquema cloud, AWS Glue y Data Pipelines, son productos de Amazon para competir con ADF. En el aspecto #OpenSource, Apache #Kafka junto a #NiFi podrían ser un competir muy digno.
Respecto a la parte de transformación, quizás pierde un poco respecto a sus competidores, por ejemplo contra #Pentaho.
La gran ventaja de los productos 100% cloud se da por la rápida integración hacia otros productos. Por ejemplo, en el caso de una plataforma de #IoT, ADF en pocos clics se integra a Azure Event Hub. O poder trabajar integrado a Azure DevOps para poder trabajar el desarrollo de las integraciones como si fuera un software normal.
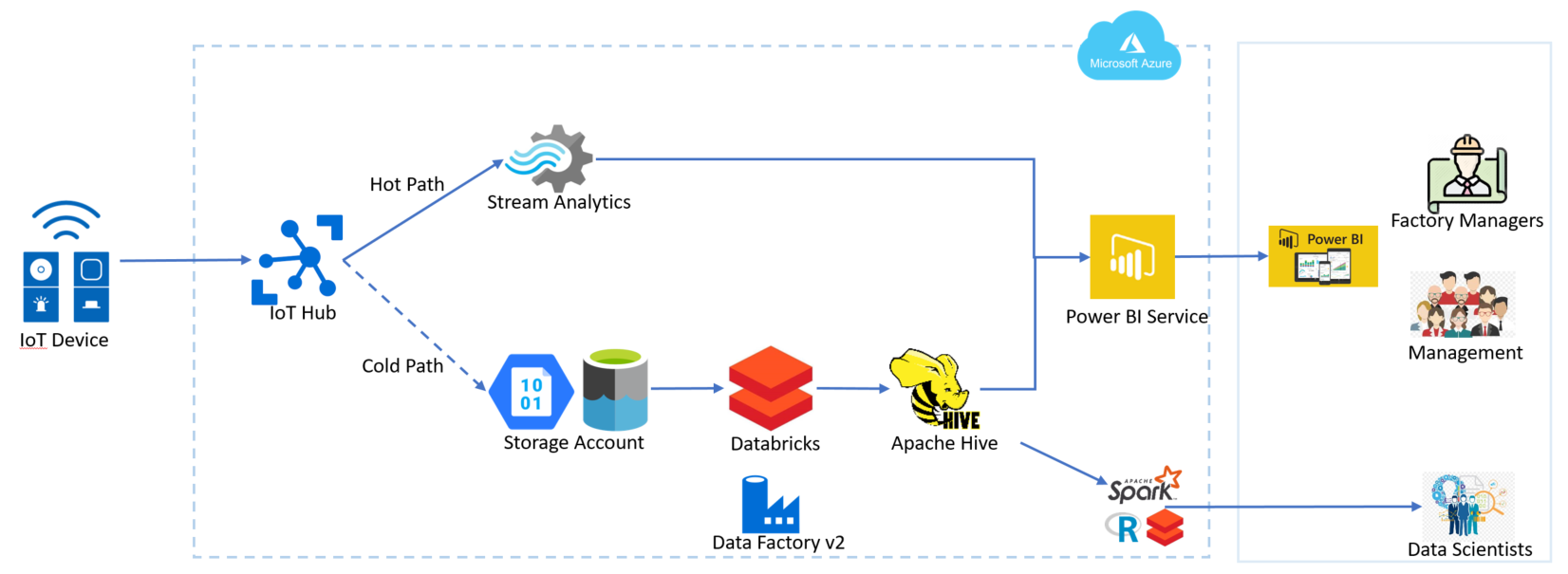
Conclusión
Este es una simple entrada para mencionar y que conozcan Azure Data Factory. Es realmente muy poderosa y su capacidad para integrarse a otras herramientas la transforma en lo que solemos llamar ‘una navaja suiza’, donde podemos tomar la informacion, procesarla, limpiarla, darle formato y enviarla a un almacenamiento destino para su uso final, ya sean tableros de BI o modelos de Machine Learning, todo como un proceso end to end.